
Spectroscopische technieken en hyperspectrale beeldverwerking kunnen gebruikt worden om bij kwaliteitscontroles informatie te verkrijgen over de samenstelling (bijvoorbeeld proteïnen, vetten, koolhydraten, vocht), veiligheid en complexe kwaliteitseigenschappen zoals textuur en sensorische eigenschappen (zie onder: ‘nuttige links’) van levensmiddelen. Veder vinden deze technieken toepassing in fraudedetectie (bijvoorbeeld: toevoeging van minderwaardige ingrediënten) en authenticiteitsbepalingen. Typisch meten deze technieken in elk meetpunt een spectrum op. Dat genereert een grote hoeveelheid data waaruit men (klassiek) door toepassing van chemometrische methoden kwaliteitsparameters tracht te voorspellen.
Chemometrie Chemometrie is een discipline in de chemie die multivariate statistische verwerkingsmethoden toepast op analytische meetgegevens om (i) gepaste meetprocedures en experimenten te selecteren of te ontwerpen en (ii) data maximaal te interpreteren naar chemische informatie toe. Dit bevat onder andere het in grootte reduceren van complexe data, het mathematisch corrigeren van interferenties bij metingen en het leggen van verbanden tussen gemeten waarden en de parameters die men wil bepalen. |
Chemometrische methoden kunnen onderverdeeld worden in twee categorieën van ‘leertechnieken’: ongecontroleerd (‘unsupervised’) of gecontroleerd (‘supervised’). Ongecontroleerd leren is gebaseerd op clusteranalyse met bijvoorbeeld ‘Principal Component Analyse’ (PCA) en deelt de set van stalen in in groepen volgens hun similariteit. De groepen kunnen in 2D gevisualiseerd worden als men de groepering uitvoert op basis van de twee voornaamste ongecorreleerde variabelen die de meeste varantie in de meetset kunnen verklaren (Principale componenten of PC’s genoemd, zie bijvoorbeeld Figuur 1).
Bij gecontroleerd leren, bepaalt men op basis van voorkennis ‘pregedetermineerde’ groepen, waarin nieuwe stalen geklasseerd worden volgens een discriminanten analyse. Interessant is dat bij gecontroleerd leren ook regressie analyse mogelijk is, bijvoorbeeld door de veel gebruikte ‘Partial Least Squares Regression’ methode (PLSR) toe te passen op een en set van goed gekarakteriseerde en welgekozen steekproefstalen. De data analyst kan de kwaliteit van de regressies beoordelen op basis van de Root Mean Squared Error (RMSE, die als maat voor de ‘onverklaarde’ variantie zo laag mogelijk moet zijn). Vervolgens dient de performantie (de mogelijkheid om te generaliseren) van de regressie (het kalibratiemodel) te worden gevalideerd door toevoeging van metingen op nieuwe, onafhankelijke (maar eveneens gekarakteriseerde) stalen (zie eerder Food Radar artikel). Specifieke aandacht moet besteed worden aan het vermijden van ‘overfitting’.
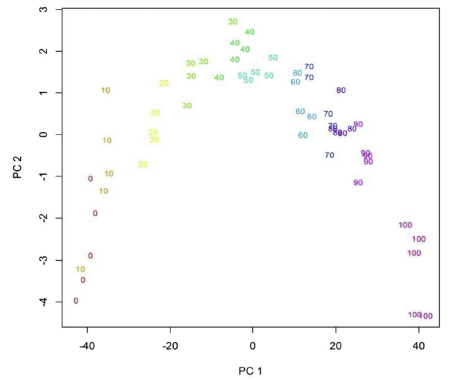
Figuur 1: Een voorbeeld van een PCA score plot van multispectraal geanalyseerde rundergehaktstalen, die al dan niet ingemengd werden met varkensgehakt (het getal geeft het % varkensgehakt weer). [Bron: Ropodi et al., 2016]
LEVERT DATAMINING MEERWAARDE?
Het is duidelijk dat niet-destructieve kwaliteitsanalyses enkel mogelijk zijn dankzij geavanceerde dataverwerking. De exponentiële groei van de hoeveelheid data die wereldwijd opgeslagen wordt heeft aanleiding geven tot het ontwikkelen van ‘big data’ analyse methoden. Het hoeft niet te verwonderen dat men dergelijke dataminingstechnieken ook tracht toe te passen op spectrale data. Het betreft dan methodes die gebaseerd zijn op de principes van Artificiële Neurale Netwerken (ANN) of Support Vector Machines (SVM), waarmee ook klassificaties en regressies mogelijk zijn. De algortimes en model training verlopen een stuk complexer en zijn computationeel veeleisender dan de chemometrische methoden. Verder is de mogelijkheid om tot een succesvol model te komen sterk afhankelijk van de grootte van de dataset.
Datamining Via datamining kan men in een grote berg data graven (mining) naar ‘onzichtbare’ waardevolle informatie. Het is een discipline in de computerwetenschappen waarin men met verschillende technieken en benaderingen, algoritmen probeert op te stellen waarmee men automatisch profielen en relaties in grote gegevensverzamelingen kan detecteren. Eens men die profielen en verbanden gevonden heeft kan men modellen bouwen (verfijnde algoritmen) die voorspellingen kunnen doen op basis van nieuwe sets van gegevens. |
De toepassing van ANN en SVM op spectroscopische en multi- of hyperspectrale datasets zijn vooralsnog beperkt onderzocht geweest. In een review artikel halen Ropodi et al (2016) volgende successvolle mogelijkheden aan:
- SVM-gebaseerede voorspelling van microbiële belading in gehakt via FT-IR spectroscopie
- ANN-gebaseerde voorspelling van smaakscores van gehakt via Raman spectroscopie
- SVM-gebaseerde voorspelling van de versheid van zalm via hyperspectrale beeldverwerking
- SVM-gebaseerde detectie van gelatine toevoeging aan garnaal via multispectrale beeldverwerking
HOE ERMEE AAN DE SLAG GAAN?
Spectrometers en multi- of hyperspectrale camera’s bevatten fabrikant-specifieke software waarmee kalibraties en metingen uitgevoerd kunnen worden en data geïnterpreteerd. Los daarvan kunnen de data ingeladen worden in computers en geëxporteerd in generieke formaten zoals ‘CSV’ (‘comma sparated values’, in geval van spectroscopie) of ‘BMP’ (‘multiple bitmap image files’ voor multi- of hyperspectrale beelden). Zo zijn ze bruikbaar voor ‘stand-alone’ chemometrische softwarepakketten zoals ‘Unscrambler’, ‘Statistica’, ‘XLSTAT’ of ‘Metaboanalyst’. Wie dieper inzicht wil verwerven in de chemometrische datainterpretatie kan terecht bij ‘MATLAB’ en ‘R’. Voor deze laatsten zijn er ook ‘toollboxen’ verkrijgbaar om aan de slag te gaan met ANN en SVM.
Data analyse omvat dus een breed spectrum aan technieken, maar evenzeer een even breed gamma aan valkuilen. Om bedrijven bij te staan in de selectie van de voor hun ‘case’ best beschikbare techniek of hulp wenst voor een correcte interpretatie van de dataverwerkinsresultaten, start Flanders’ FOOD in het najaar met het ‘2-DIGIT’ project. Voor meer informatie kan u terecht bij: lieselotte.geerts@flandersfood.com, veerle.degraef@flandersfood.com, stijn.luca@kuleuven.be of bart.deketelaere@kuleuven.be.
BRON
Ropodi A.I., Panagou E.Z., Nychas G.-J.E. (2016). Data mining derived from food analyses using non-invasive/non-destructive analytical techniques; determination of food authenticity, quality & safety in tandem with computer science disciplines. Trends in Food Science & Technology, 50, 11-25.
Nuttige links
- http://flandersfood.com/artikel/2015/07/10/big-data-big-food-van-meten-naar-weten-procesoptimalisering-en-kostenreductie
- http://flandersfood.com/artikel/2015/05/27/hoe-authentiek-ons-voedsel-een-spectraal-antwoord-op-voedselfraude
- http://flandersfood.com/artikel/2014/11/12/versheid-van-vis-door-de-ogen-van-een-kreeft
- http://flandersfood.com/artikel/2014/10/07/draagbare-spectroscopische-sensorsystemen-voor-de-voedingsindustrie-hoe-ver-staan
- http://flandersfood.com/artikel/2014/09/23/pat-ondersteunde-procesbeheersing-kan-voeding-de-farma-achterna
- http://flandersfood.com/artikel/2013/05/30/beeldspectroscopie-aan-videosnelheid
- http://flandersfood.com/artikel/2013/01/24/snelle-chemische-kwaliteitsbepalingen-met-behulp-van-ftir-spectroscopie
- http://flandersfood.com/artikel/2012/07/05/continue-samenstellingsbepaling-van-melkstromen-met-visnir-spectroscopie-een-kwes
- http://flandersfood.com/artikel/2012/06/21/nir-spectroscopie-neem-de-validatieprocedure-eens-onder-de-loep
- http://flandersfood.com/artikel/2012/01/12/een-hyperspectrale-kijk-op-vleeskwaliteit
- http://flandersfood.com/artikel/2011/09/15/traceren-van-contaminatiebronnen-ft-ir
- http://flandersfood.com/artikel/2011/07/07/spectroscopie-monitort-de-voor-de-consument-belangrijke-kwaliteitskarakteristieke
- http://flandersfood.com/artikel/2009/04/16/hyperspectra-imaging-toekomstmuziek-voedingsindustrie
- http://flandersfood.com/artikel/2009/04/02/toepassingen-van-nir-spectroscopie-de-voedingsindustrie
